JEN-1 is a cutting-edge AI-powered music generation framework that redefines how music is created, customized, and composed. It combines state-of-the-art diffusion models with advanced learning techniques to enable high-fidelity text-to-music generation, personalized musical concept adaptation, and controllable multi-track composition. JEN-1 excels in producing expressive music from text prompts, capturing unique musical styles from reference tracks, and facilitating human-AI co-composition workflows. With innovations like omnidirectional diffusion modeling, pivotal parameter tuning, and curriculum training for multi-track synthesis, JEN-1 sets a new benchmark for interactive and customizable AI-driven music creation. Experience the future of AI-driven music creation at JEN Music AI https://www.jenmusic.ai/.
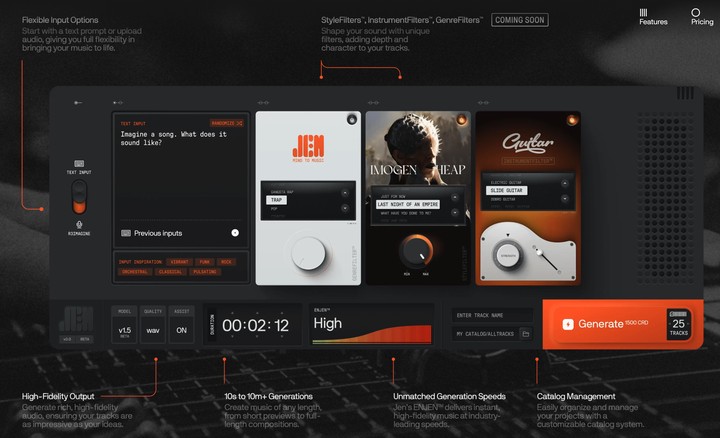 Photo by rawpixel on Unsplash
Photo by rawpixel on Unsplash
Peike Li ☮️
Research Scientist @ Google | Scaling World Models for ASI
Peike Li is a Research Scientist at Google Research.