Going Deeper into Embedding Learning for Video Object Segmentation
Abstract
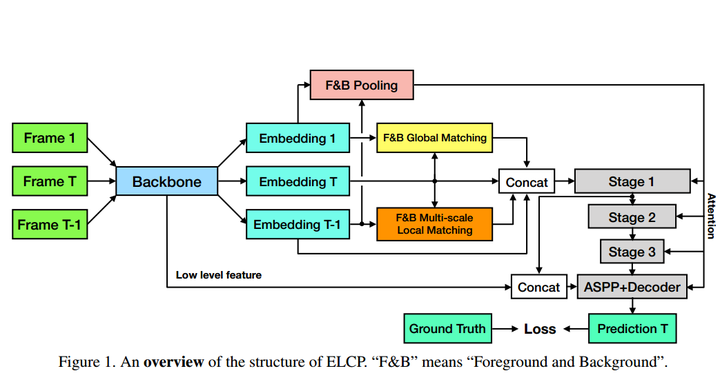
In this paper, we investigate the principles of consis-tent training, between given reference and predicted se-quence, for better embedding learning of semi-supervisedvideo object segmentation. To accurately segment the tar-get objects given the mask at the first frame, we realizethat the expected feature embeddings of any consecutiveframes should satisfy the following properties: 1)globalconsistency in terms of both foreground object(s) and back-ground; 2)robust local consistency under a various objectmoving rate; 3)environment consistency between the train-ing and inference process; 4)receptive consistency betweenthe receptive fields of network and the variable scales ofobjects;5)sampling consistency between foreground andbackground pixels to avoid training bias. With the princi-ples in mind, we carefully design a simple pipeline to liftboth accuracy and efficiency for video object segmentationeffectively. With the ResNet-101 as the backbone, our singlemodel achieves a J&F score of 81.0% on the validation setof Youtube-VOS benchmark without any bells and whistles.By applying multi-scale & flip augmentation at the testingstage, the accuracy can be further boosted to 82.4%. Codewill be made available.