🍔In-N-Out Generative Learning for Dense Unsupervised Video Segmentation
Abstract
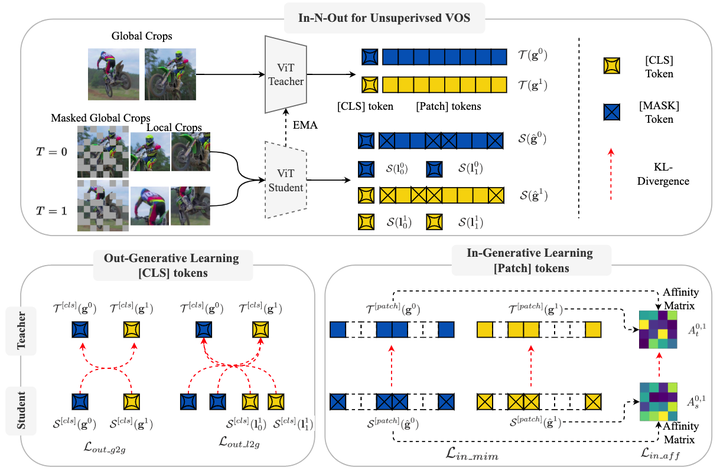
In this paper, we focus on the unsupervised Video Object Segmentation (VOS) task which learns visual correspondence from unlabeled videos. Different from the previous methods which are mainly based on the contrastive learning paradigm, we propose the In-aNd-Out (INO) generative learning from a purely generative perspective. Our proposed INO captures both the high-level and fine-grained semantics, composing of the in-generative and out-generative learning. Specifically, the in-generative learning recovers the corrupted parts of an image via inferring its fine-grained semantic structure, while the out-generative learning captures high-level semantics by imagining the global information of an image given only random fragments. To better discover the temporal information, we additionally force the inter-frame consistency from both feature level and affinity matrix level. Extensive experiments on DAVIS-2017 val and YouTube-VOS 2018 val show that our INO outperforms previous state-of-the-art methods by significant margins.