SFGN: Representing the Sequence with One Super Frame
Abstract
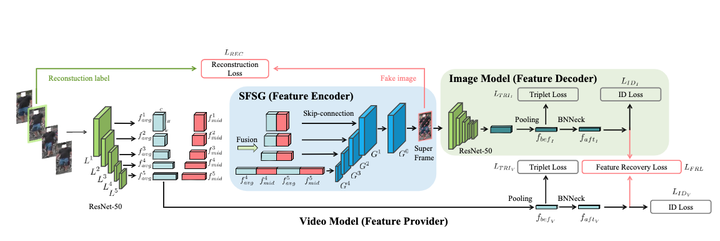
Video-based person re-identification (V-Re-ID) is more robust than image-based person re-identification (I-Re-ID) due to the additional temporal information. However, the high storage overhead of video sequences largely stems the applications of V-Re-ID. To reduce the storage overhead, we propose to represent each video sequence with only one frame. However, directly picking one frame from each sequence will dramatically decrease the performance. Thus, we propose a brand-new framework called super frame generation network (SFGN) which can encode the spatial-temporal information of a video sequence into a generated frame, which is called super frame to distinguish from the directly picked key frame. To achieve super frames of high visual quality and representation ability, we carefully design the specific-frame-feature fused skip-connection generator (SFSG). SFSG takes the role of a feature encoder and the co-trained image model can be seen as the corresponding feature decoder. To reduce the information loss in the encoding-decoding process, we further propose the feature recovery loss (FRL). To the best of our knowledge, we are the first to propose and relieve this issue. Extensive experiments on Mars, iLIDS-VID and PRID2011 show that the proposed SFGN can generate super frames of high visual quality and representation ability. The code will be released after the review.