Super-Resolving Cross-Domain Face Miniatures by Peeking at One-Shot Exemplar
Abstract
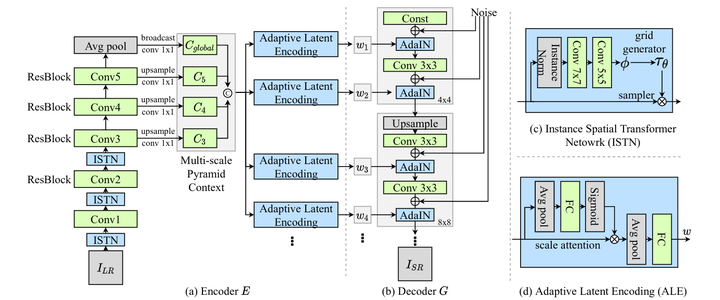
Conventional face super-resolution methods usually assume testing low-resolution (LR) images lie on the same domain as the training ones. Due to different lighting conditions and imaging hardware, domain gaps between training and testing images inevitably occur in many real-world scenarios. Neglecting those domain gaps would lead to inferior face super-resolution (FSR) performance. However, collecting large-scale data from a target domain to re-train FSR models is often time-consuming. Therefore, we aim to employ only few examples, ideally one-shot exemplar, to adapt an FSR model to a target domain rapidly. In this paper, we propose a domain-aware pyramid-based face super-resolution network, named DAP-FSR network, to super-resolve LR faces from a new domain by exploiting one paired high-resolution (HR) and LR exemplar in the target domain. When a target domain LR face is given, our DAP-FSR firstly employs its encoder extracts the multi-scale latent representations of the input face. Considering only one target domain example is available, we augment the target domain data by mixing the latent representations of the target domain face and source domain ones, and then feed the mixed representations to the decoder of our DAP-FSR. The decoder will generate new face images resembling the given target domain image. The generated HR faces in return are used to optimize our decoder to reduce the domain gap. By iteratively updating the latent representations and our decoder, our DAP-FSR will be adapted to the target domain, thus achieving authentic and high-quality upsampled HR faces. Extensive experiments on three newly constructed benchmarks validate the effectiveness and superior performance of our proposed DAP-FSR compared to the state-of-the-art methods.